SAI RAJESWAR

I am a Staff Research Scientist and Research Lead at ServiceNow, as well as an Adjunct professor and a core industry member at Mila Montréal. My work over the last ten years spans broadly generative models and reinforcement learning, trying to chase human-like intelligence. Lately, I have been focusing on Multimodal perception and world representations that I believe are key for generalist AI systems that integrate perception and action while incorporating feedback from the environment.
I obtained my Ph.D. at MILA, University of Montreal, supervised by Prof.Aaron Courville. where I am included in the Dean’s Honor List for the graduating year 2022-23. During my Ph.D. I had an opportunity to spend time as a Research Scientist Intern at Google DeepMind. Previously, I obtained masters in computer science from IIT Delhi, where I was a recipeint of Prof. A.K.Sinha best student award for the graduating year 2015-16.
- If the following line of work interests you and you would like to explore fundamental research questions around these, collaborate or receive mentorship, feel free to reach out.
![]()

![]()

Recent Research (To be Updated). See Google Scholar page for more recent research.
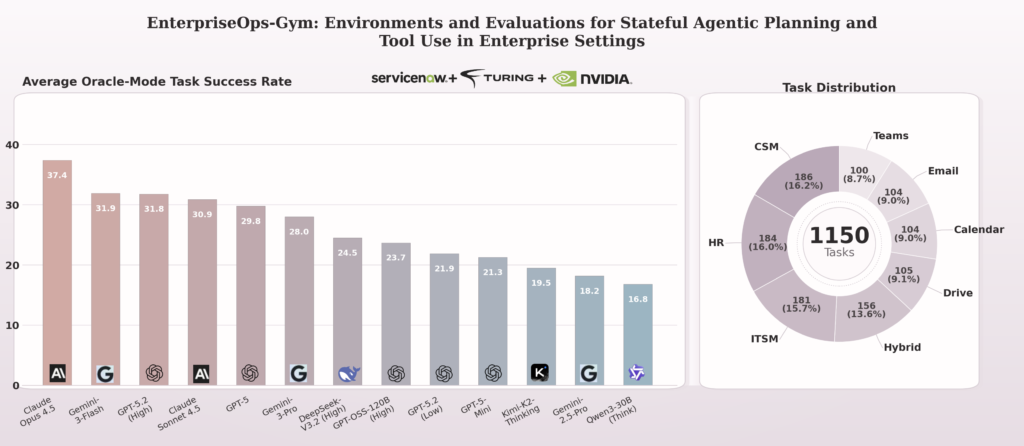
EnterpriseOps-Gym: Environments and Evaluations for Stateful Agentic Planning and Tool Use in Enterprise Settings. (under review). Paper, Page
We study whether agents are ready for real enterprise work.
Reliable automation is still far from solved. We released our largest, most realistic environment to evaluate long-horizon agent planning tool execution under real enterprise constraints.
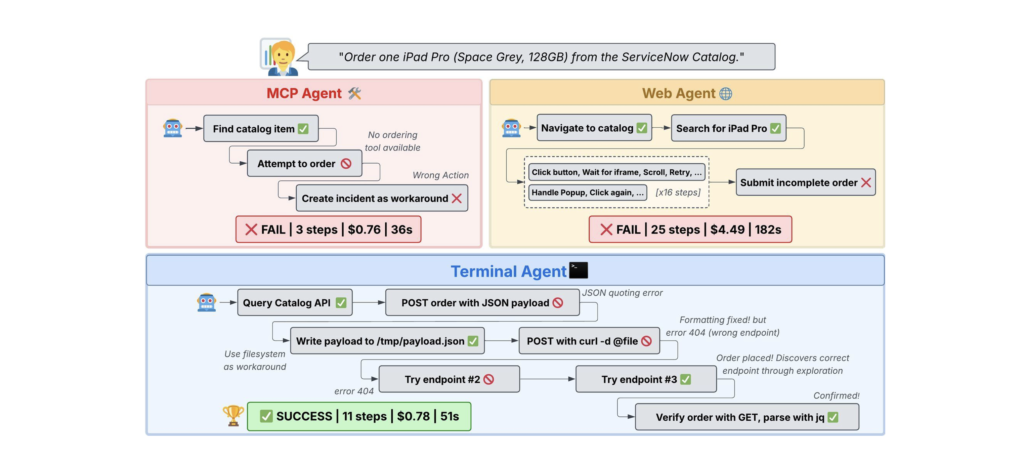
Terminal Agents Suffice for Enterprise Automation. under review. Paper
Terminal-based coding agents with direct API access match or outperform complex MCP and GUI agents, proving that strong foundation models need only simple programmatic interfaces for enterprise automation. Terminal agents achieve the same accuracy as web agents but are 5 to 6x cheaper and outperform MCP agents while staying cost-neutral.
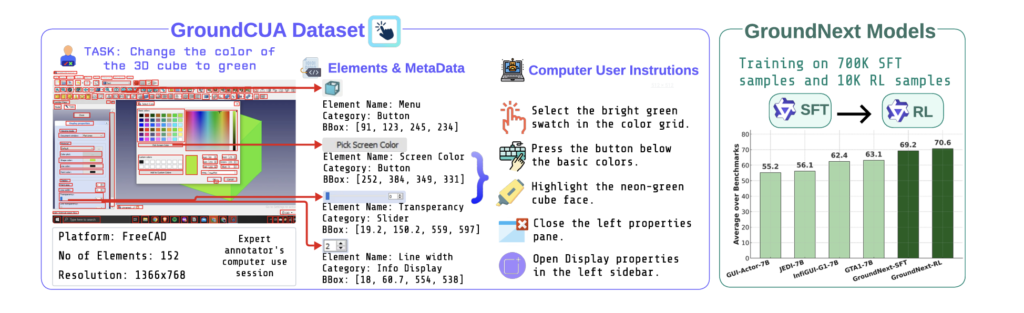
Grounding Computer Use Agents on Human Demonstrations. ICLR 2026. Paper
Building reliable computer-use agents requires accurately connecting natural language instructions to the correct on-screen elements. We introduce GroundCUA, large-scale dataset & GroundNext family of models.
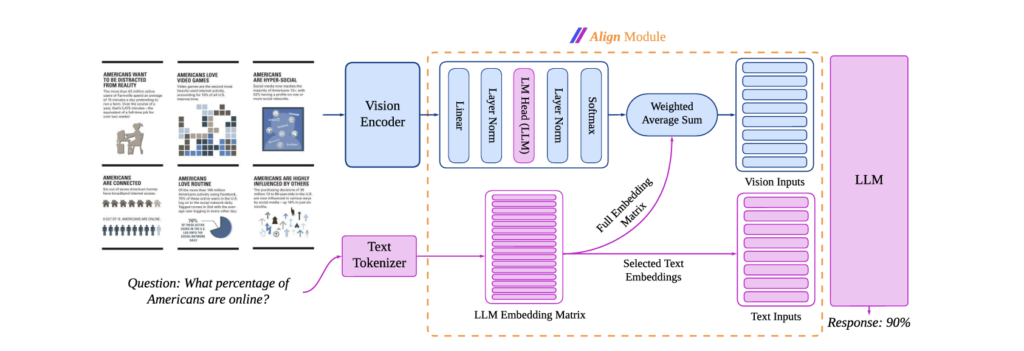
AlignVLM:BridgingVision and Language Latent Spaces for Multimodal Understanding. NeurIPS 2025. Paper
A novel approach to bridging vision and language latent spaces for multimodal understanding in VLMs that maps vision features into a weighted average of LLM text embeddings, ensuring they remain in a space that the LLM can effectively interpret.
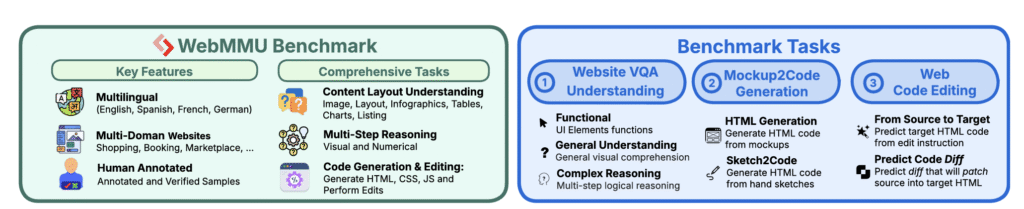
WebMMU: A Multimodal, Multilingual Benchmark for Website Understanding & Code Generation. EMNLP 2025 (Oral). Page
Adress a critical gap in AI evals: how well can models understand and build websites. Unlike many recent works, we collected a real-world, challenging dataset with 117 expert annotators across diverse domains. Its Multilingual.
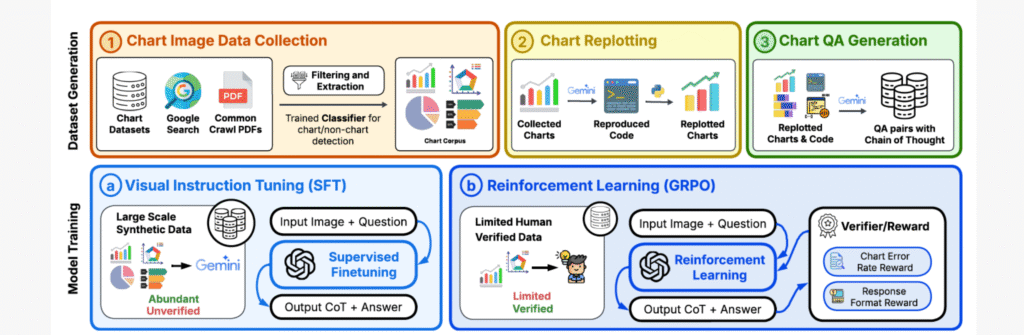
BigCharts-R1: Enhanced Chart Reasoning with Visual Reinforcement Finetuning. CoLM 2025. Page
Chart comprehension is crucial for effective human decision-making, yet current VLMs struggle with this task due to limitations in training data and methodologies. We introduce BigCharts-R1, a state-of-the-art chart reasoning model, alongside a novel dataset and training framework.

UI-Vision: A Desktop-centric GUI Benchmark for Visual Perception and Interaction. ICML 2025. Page
first comprehensive, license-permissive benchmark for offline, fine-grained evaluation of CUA agents in real-world desktops. We provides: (i) dense, high-quality annotations of human demonstrations, including bounding boxes, UI labels, and action trajectories across 83 software applications.
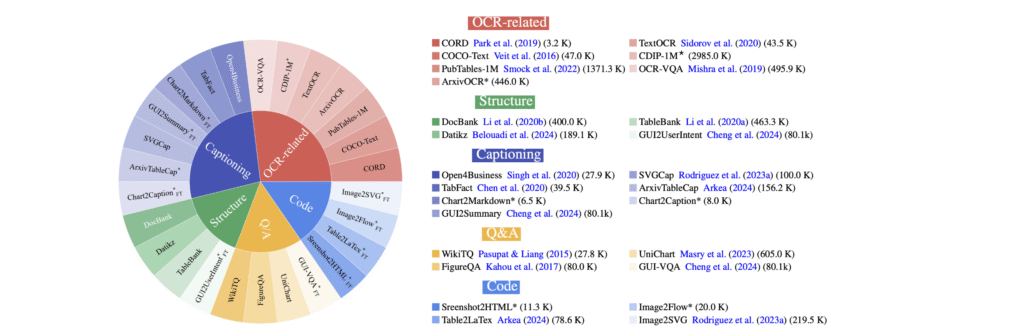
BigDocs: An Open Dataset for Training Multimodal Models on Document and Code Tasks. ICLR 2025. Page
BigDocs is a multimodal dataset effort for advanced document understanding, consisting of two key components: BigDocs-7.5M: A high-quality, open-access, large-scale dataset of 7.5 million multimodal documents spanning 30 tasks BigDocs-Bench: A benchmark suite with 10 real-world-inspired tasks like reasoning over graphical user interfaces (GUI).

GenRL: MULTIMODAL FOUNDATION WORLD MODELS FOR GENERALIST EMBODIED AGENTS. NeurIPS 2024
GenRL allows one to specify tasks through vision and/or language prompts, ground them in the embodied domain’s dynamics, and learns the corresponding behaviors in imagination. This exhibits strong multi-task generalization in locomotion and manipulation domains. Read more.
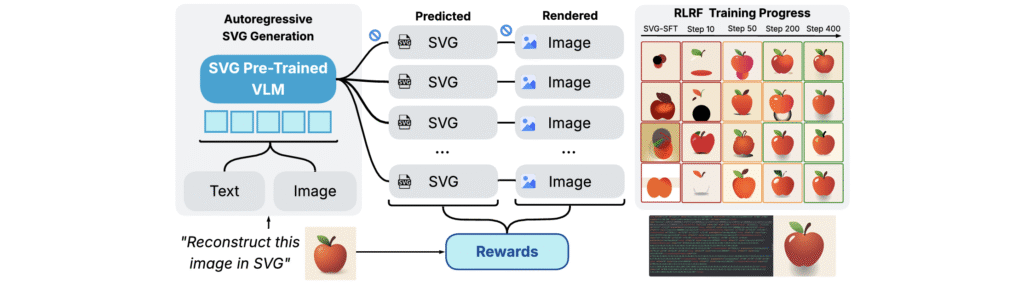
Rendering-Aware Reinforcement Learning for Vector Graphics Generation. NeurIPS 2025
RL way to enhances SVG generation in autoregressive VLMs by leveraging feedback from rendered SVGoutputs. SVG roll-outs are rendered and compared to original image to compute a reward. This visual fidelity feedback guides model to produce more semantically coherent SVGs.

StarVector: Generating Scalable Vector Graphics Code From Images And Text CVPR 2025
GenRL allows one to specify tasks through vision and/or language prompts, ground them in the embodied domain’s dynamics, and learns the corresponding behaviors in imagination. This exhibits strong multi-task generalization in locomotion and manipulation domains. Read more.

REPRESENTING POSITIONAL INFORMATION IN GENERATIVE WORLD MODELS FOR OBJECT MANIPULATION
We introduce a general approach that empowers world model-based agents to effectively solve object-positioning tasks. We propose two declinations of this approach for generative world models: position-conditioned (PCP) and latent-conditioned (LCP) policy learning Read more.
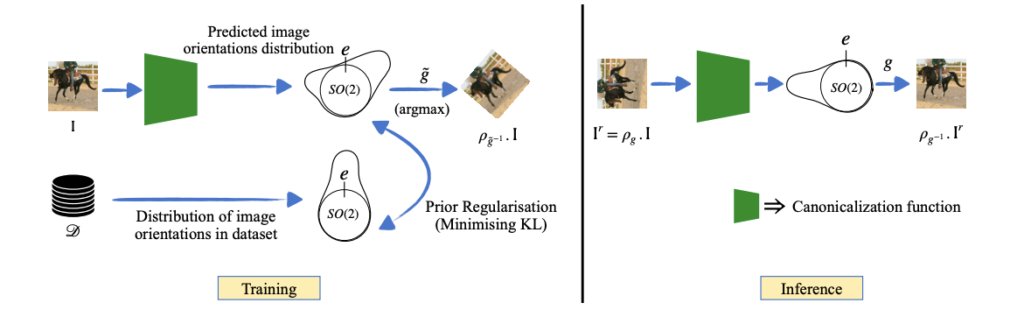
EQUIVARIANT ADAPTATION OF LARGE PRETRAINED MODELS. NeurIPS 2023
Equivariant networks are specifically designed to ensure consistent behavior with respect to a set of input transformations, leading to higher sample efficiency and more accurate and robust predictions. Read more
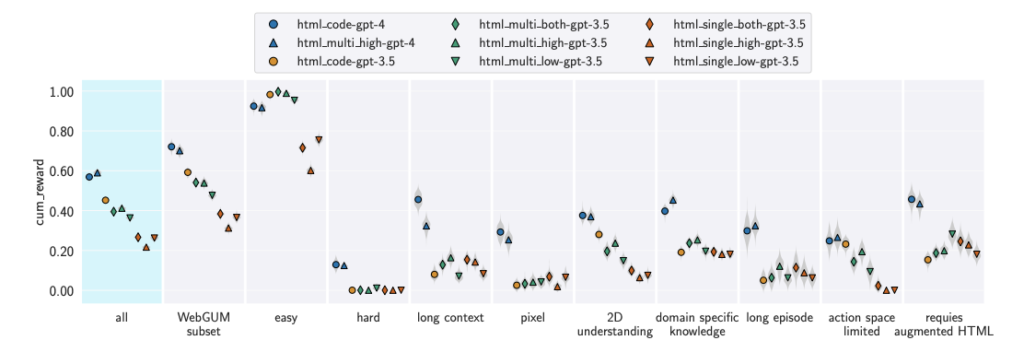
THE UNSOLVED CHALLENGES OF LLMS AS GENERALIST WEB AGENTS: A CASE STUDY
In this work, we investigate the challenges associated with developing goal-driven AI agents capable of performing novel tasks in a web environment using zero-shot learning. Our primary focus is on harnessing the capabilities of large language models (LLMs) as generalist web agents interacting with HTML-based user interfaces (UIs). Read more

MASTERING THE USUPERVISED REINFORCEMENT LEARNING FROM PIXELS. ICML 2023 (Oral)
In this work, we study the URLB and propose a new method
to solve it, using unsupervised model-based RL, for pre-training the agent, and a task-aware finetuning strategy combined with a new proposed hybrid planner, Dyna-MPC, to adapt the agent for downstream tasks. Read more

CHOREOGRAPHER: LEARNING & ADAPTING SKILLS IN IMAGINATION. ICLR 2024 (Spotlight)
a model-based agent that exploits its world model to learn and adapt skills in imagination. We decouple the exploration and skill learning processes, being able to discover skills in the latent state space. During adaptation, the agent uses a meta-controller to evaluate and adapt the learned skills efficiently by deploying them in parallel in imagination. Read more

EFFICIENT DYNAMICS MODELING IN INTERACTIVE ENVIRONMENTS WITH KOOPMAN THEORY, ICLR 2024
We approach this problem from the lens of Koopman theory, where the
nonlinear dynamics of the environment can be linearized in a high-dimensional latent space. This allows us to efficiently parallelize the sequential problem of long-range prediction using convolution while accounting for the agent’s action at every time step. Read more

Multi-label Iterated Learning for Image Classification with Label Ambiguity, CVPR 2022
Transfer learning from large-scale pre-trained models has become essential for many computer vision tasks. Recent studies have shown that datasets like ImageNet are weakly labeled since images with multiple object classes present are assigned a single label. Inspired by language emergence literature, we propose MILe to incorporate the inductive biases of multi-label learning from single labels using iterated learning. Read more
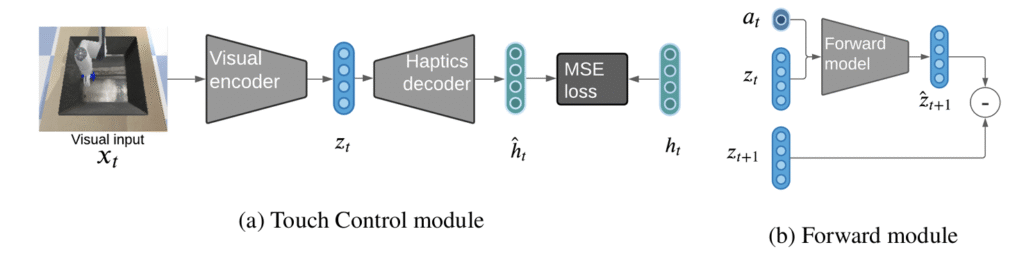
Touch based Curiosity for Sparse-Reward Tasks, CoRL 2023
we leverage surprise from mismatches in touch feedback to guide exploration in hard sparse-reward reinforcement learning tasks. Our approach, Touch-based Curiosity (ToC), learns what visible objects interactions are supposed to “feel” like. We encourage exploration by rewarding interactions where the experience do not match. We test on a range of touch-intensive robot tasks (e.g. pushing objects, opening doors)